My latest overview post on Justia’s Legal Marketing and Technology Blog is all about the Robots Exclusion Standard. I explain reasons why you may need to block certain content from search engines, as well as explain the different mechanisms available to you to do so. Check it out!
In general, web-based marketing is all about getting search engines to index your content. However, there are certain circumstances when you may not want search engines to index some of your content. Learn about the robots exclusion standard, when and how to use it, and some of the nuances associated with using it and other exclusion protocols as part of your overall marketing strategy.
A key component of Search Engine Optimization is ensuring that your content gets indexed by search engines and ranks well, but there are legitimate reasons you might want some of your content not to be listed in search engines. Fortunately, there is a mechanism in place known as the robots exclusion standard to help you block content from search engines. There are multiple ways to implement the robots exclusion standard, and which one you use will vary depending on the type of content you want to block and your specific goal in blocking it.
Reasons to Block Content From Search Engines
Under Development
Websites can take a long time to create or update, and often you may want to share the progress of the site with other people while you are working on it. The most common way to handle this is to create a development or staging copy of your site and make your changes to this copy before going live with them. Because this is an incomplete site and its contents are likely duplicative of the contents of your live site, you don’t want your potential clients to find this incomplete version of your site. As such when you set up a development copy of your site, you should use one or more of the methods below to block your entire development copy from search engine spiders.
Private Content
If the content of a particular page is of a private nature, you may want to block this page from being indexed by search engines. In general, content blocked from search engines is available only to people who have been directly given the link. It is important to note however that using the robots exclusion standard to block search engines from indexing a page does not prevent unauthorized access to the page. Thus, if the content is sensitive, you should not only block the content from search engines using the robots exclusion standard but also use an authentication scheme to block the content from unauthorized visitors as well.
Dynamic Content
If you have content on your site that is ephemeral in nature, changing constantly, you may want to block search engines from indexing content that will soon be obsolete. Search Engines often take time to index updated content, so if your content changes regularly, you may feel it important to block the ephemeral content from being indexed to prevent outdated content from coming up in search.
Purposefully Duplicate Content
We’ve explained before the importance of having original, rather than duplicate, content. In some situations, however, you may have a legitimate reason for one page on your site to have content that is duplicative of another page (either yours or not), so to prevent any duplicate content penalties, you may wish to block this duplicate content from search engines. You should note that there are other, better, ways to handle duplicate content in general. In particular, the <link rel="canonical"> tag allows you to explicitly say that the content of the page the spider has hit is a duplicate of another more “official” page. For example, we have clients with multiple websites, and for particular pages on their site, they would like the main site version indexed. In these cases, we set up the proper canonical tags so the search engines recognize only the page they want.
But if you just want to make sure your duplicate page doesn’t rank at all, excluding search engine robots using the robots exclusion standard may be your best option.
Advertising Landing Pages
When setting up an advertising campaign, such as cost-per-click, email newsletters, offline, print, or television, you may want to send visitors acquired through that campaign to a page specifically designed to match the message of the advertisement. Often the content of this page is either duplicative of other pages of your site (e.g., similar content but tailored to a single geographical area), or specific to the particular advertisement (e.g., with a special discount code). In these cases, you may want to ensure the only way people get to this content is through that advertisement. For our clients who have specific pages like this for advertising, we use the robots exclusion standard to block search engines from indexing these landing pages.
How to block something from search engines
robots.txt
The oldest and most widely known mechanism for blocking content from search engine bots is a plain text file in the root of your website named robots.txt. This file is plain text (no HTML) and simply lists the pages you don’t want search engine (or other) robots to hit. The robots.txt file is split up into sections, with each section targeting a different robot. You divide your sections with a line that reads:
User-agent: [robotname]For example, to indicate that this section is for Google, you would use User-agent: Googlebot
If you want the rules of the section to apply to every possible bot, you can create a section named User-agent: *
Inside each section you can have any number of Allow: and Disallow: lines indicating that the indicated page should or should not be indexed by the search engine/robot in question. You should note however, that a robot will only read the first section they find that matches their own user agent, so if you have something like this:
User-agent: Googlebot
Disallow: /nogoogle.html
Allow: /
User-agent: *
Disallow: /nobody.html
Allow: /Google will not read the blocking of /nobody.html and Google’s robot will access that page. In order to block all robots from accessing /nobody.html and only Google’s robot from accessing /nogoogle.html, you would need to write the following:
User-agent: Googlebot
Disallow: /nogoogle.html
Disallow: /nobody.html
Allow: /
User-agent: *
Disallow: /nobody.html
Allow: /This code will instruct Google’s robot not to access /nogoogle.html or /nobody.html, but will allow other search engines to access /nogoogle.html. Although not all robots understand Allow: and instead only understand Disallow: lines, most modern large-scale robots do understand this syntax.
Non-Standard robots.txt Extensions
The aforementioned Allow: directive was created by Google as a way to create an exception-based system (block all urls matching this pattern except for this more specific url which you can allow). Search engines that don’t support the Allow: directive will generally simply ignore those lines, so be sure if you use it that you are taking into consideration any robots that may not support it.
There are a number of other extensions to robots.txt that not all search engines support, but some of them may still be useful to know.
Sitemap: is a popular extension to robots.txt (highly recommended by both Google and Bing). This extension allows you to specify the URL of your sitemap file inside your robots.txt. This allows search engines that support this directive to locate and index your sitemap even if you don’t specifically submit your sitemap to them.
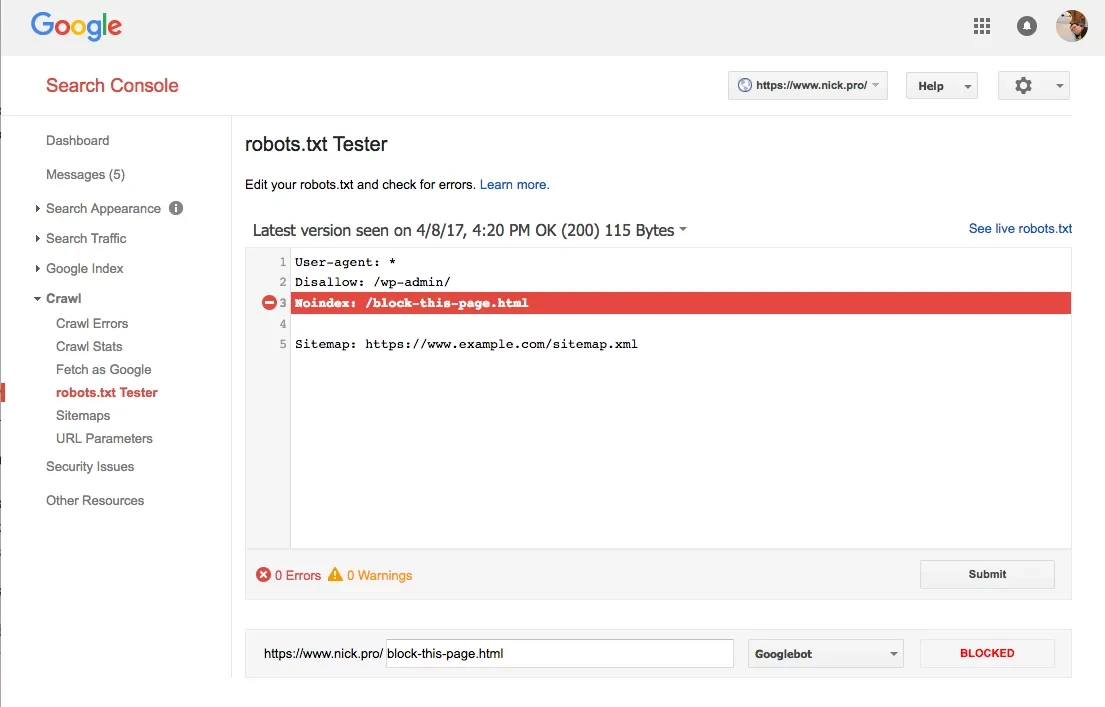
Noindex: is an undocumented (and unsupported) directive that Google engineers have mentioned a few times in the past (Matt Cutts mentioned this on his personal blog in 2008, and John Mueller mentioned it in a Webmaster’s Hangout in 2015). This directive works much like the robots noindex meta tag or http header described below in that it explicitly lists the URLs that Google should not index (to clarify, Disallow: means that spiders are not allowed to visit the page, however they can index the page if they discover it without visiting, Noindex: means that search engines are not allowed to index the page at all) It is important to note however that the official Google webmasters documentation does not mention the Noindex: directive. On the contrary, their main documentation page about robots.txt files says (emphasis in original):
For non-image files (that is, web pages) robots.txt should only be used to control crawling traffic, typically because you don’t want your server to be overwhelmed by Google’s crawler or to waste crawl budget crawling unimportant or similar pages on your site. You should not use robots.txt as a means to hide your web pages from Google Search results. This is because other pages might point to your page, and your page could get indexed that way, avoiding the robots.txt file. If you want to block your page from search results, use another method such as password protection or noindex tags or directives.
Currently, the robots.txt tester inside Google Search Console does still recognize Noindex: as a valid directive, but given that Google has never documented this directive, we would not recommend relying on it.
UPDATE July, 2019: Google has announced that they are removing support for
Noindex:from Googlebot effective September 1, 2019. We have a full write up of this and other changes to the way Google handles robots.txt on this blog.
Meta Robots tag
Unlike the robots.txt file, the <meta name="robots"> tag allows you to explicitly say which pages can be indexed in search engines, and whether a search engine is allowed to follow any links on the page to any other pages. There are a number of possible values to put in the meta robots tag, but for the purpose of this article we’ll focus on the four most common values (which are paired).
index / noindex : this indicates whether the page the robot is reading should be indexed or not (index for yes, noindex for no)
follow / nofollow : this indicates whether the robot should follow any of the links on this page.
<meta name="robots" content="noindex, follow" />This tag means that the search engine robot should not index the current page, but should follow any links on the page to find other pages to index.
<meta name="robots" content="noindex, nofollow" />This tag means that the search engine robot should not index the current page, and should not follow any of the links on the page to get to other pages.
You can target a rule at a particular robot by replacing the word “robots” in the name with an appropriate name for the search engine in question.
<meta name="googlebot" content="noindex, nofollow" />
<meta name="robots" content="index, follow" />A page containing these two tags would be blocked from Google, but not blocked on other search engines. Unlike with the robots.txt file, the order in which the tags are written does not matter; a robot will look for the most specific applicable tag.
X-Robots-Tag HTTP Header
Meta robots is a perfect solution in that it is explicit in telling the robots what to do with the HTML page they are parsing, but not all content on the web is HTML. If you want to set these types of rules for images or pdf documents (or any other type of file other than HTML files), many search engines are now allowing you to set an HTTP header on your server to pass the same rules back.
X-Robots-Tag: noindex, nofollowThis HTTP header has the same effect as a <meta name="robots" content="noindex, nofollow" /> except that it also works on non-HTML content.
How you set these HTTP headers varies depending on your web server and your content management system, but they can be set by all of the popular web server softwares and most programming languages that can output web content.
Other ways to block a page
There are other, more elaborate, ways to block pages from search engines. You can make sure that your content outputs a 404 or 410 status code so that the robots think your content isn’t there, you can lock your content behind a 401 authorization header so that nobody, including search engines, can access the page to read it, or you can repeatedly use your search engine’s webmaster portal (Google Search Console, Bing Webmaster Tools, etc.) to remove the page from their index manually.
Removing already indexed content
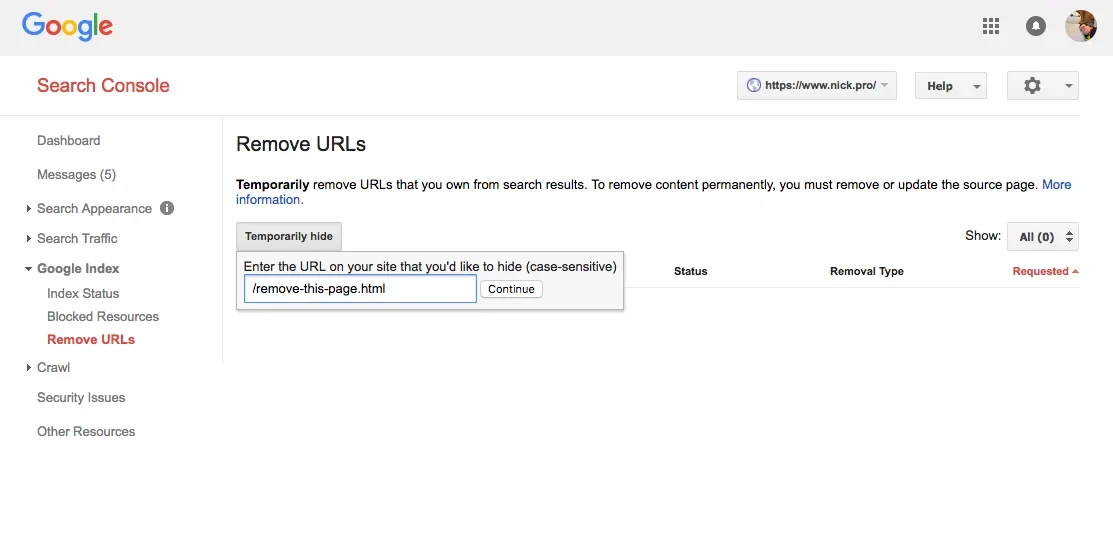
After you’ve set up your robots blocking mechanism, if the content has already been indexed, you may notice that it takes a long time for the content to fall out of search engines. As mentioned above, the major search engines have webmaster portals that allow you to request that your content be removed from the search engines.
While most search engines will allow you to submit a removal request even if you haven’t implemented a robots exclusion standard on the content, these types of removals are only temporary (blocking the content for only 90 days). It is therefore important that you not only submit the request, but that you also implement one of the blocking mechanisms mentioned above.
A Word of Caution
Using the robots exclusion standard to block content from search engines is not something to be taken lightly. It is important to be sure that you have carefully tailored your robots exclusions only to the content you want not to be indexed. Using a directive like Disallow: / in your robots.txt file will block your entire site from search engines, which will almost certainly result in a significant drop in traffic.
Also, you should be aware when blocking content, in particular non-HTML content (images, css files, javascript files, etc), that the robots have no context as to why you are blocking this content and the various webmaster consoles mentioned earlier may send you warnings to be sure you really did intend on blocking the content in question.
At Justia, we follow Google and other search engine guidelines and code our clients’ sites for optimal visibility. We also know how to properly block or remove any content from the search engines when the need arises. If you are looking to update your website to stay on top of the latest technologies, contact us to see how we can help. We have an unparalleled record in helping law firms grow.